Unit 4: Reading and Writing Notes
1.3 Processing Boolean queries
The intersection is the crucial one: we need to efficiently intersect postings lists so as to be able to quickly find documents that contain both terms.
There is a simple and effective method of intersecting postings lists using the merge algorithm: we maintain pointers into both lists and walk through the two postings lists simultaneously, in time linear in the total number of postings entries.
Query optimization is the process of selecting how to organize the work of answering a query so that the least total amount of work needs to be done by the system. A major element of this for Boolean queries is the order in which postings lists are accessed.
if we start by intersecting the two smallest postings lists, then all intermediate results must be no bigger than the smallest postings list, and we are therefore likely to do the least amount of total work.
For arbitrary Boolean queries, we have to evaluate and temporarily store the answers for intermediate expressions in a complex expression. However, in many circumstances, either because of the nature of the query language, or just because this is the most common type of query that users submit, a query is purely conjunctive.
1.4 The extended Boolean model versus ranked retrieval
The Boolean retrieval model contrasts with ranked retrieval models such as the vector space model, in which users largely use free text queries , that is, just typing one or more words rather than using a precise language with operators for building up query expressions, and the system decides which documents best satisfy the query.
Many users, particularly professionals, prefer Boolean query models. Boolean queries are precise: a document either matches the query or it does not. This offers the user greater control and transparency over what is retrieved. And some domains, such as legal materials, allow an effective means of document ranking within a Boolean model
6 Scoring, term weighting and the vector space model
Thus far we have dealt with indexes that support Boolean queries: a document either matches or does not match a query. In the case of large document collections, the resulting number of matching documents can far exceed the number a human user could possibly sift through.
- parametric and zone indexes
index and retrieve documents by metadata such as the language in which a document is written.
simple means for scoring
- weighting
- compute a score between a query and each document
- develops several variants of term-weighting for the vector space model.
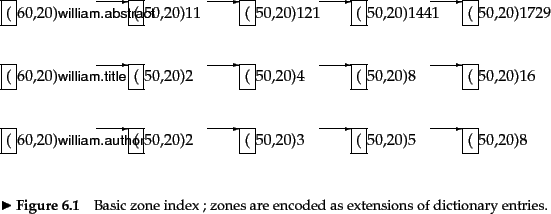
parametric and zone indexes
parametric indexes There is one parametric index for each field.
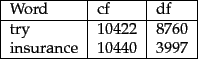
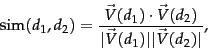
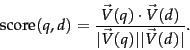
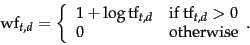
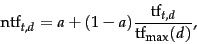

The intersection is the crucial one: we need to efficiently intersect postings lists so as to be able to quickly find documents that contain both terms.
There is a simple and effective method of intersecting postings lists using the merge algorithm: we maintain pointers into both lists and walk through the two postings lists simultaneously, in time linear in the total number of postings entries.
Query optimization is the process of selecting how to organize the work of answering a query so that the least total amount of work needs to be done by the system. A major element of this for Boolean queries is the order in which postings lists are accessed.
if we start by intersecting the two smallest postings lists, then all intermediate results must be no bigger than the smallest postings list, and we are therefore likely to do the least amount of total work.
For arbitrary Boolean queries, we have to evaluate and temporarily store the answers for intermediate expressions in a complex expression. However, in many circumstances, either because of the nature of the query language, or just because this is the most common type of query that users submit, a query is purely conjunctive.
1.4 The extended Boolean model versus ranked retrieval
The Boolean retrieval model contrasts with ranked retrieval models such as the vector space model, in which users largely use free text queries , that is, just typing one or more words rather than using a precise language with operators for building up query expressions, and the system decides which documents best satisfy the query.
Many users, particularly professionals, prefer Boolean query models. Boolean queries are precise: a document either matches the query or it does not. This offers the user greater control and transparency over what is retrieved. And some domains, such as legal materials, allow an effective means of document ranking within a Boolean model
6 Scoring, term weighting and the vector space model
Thus far we have dealt with indexes that support Boolean queries: a document either matches or does not match a query. In the case of large document collections, the resulting number of matching documents can far exceed the number a human user could possibly sift through.
- parametric and zone indexes
index and retrieve documents by metadata such as the language in which a document is written.
simple means for scoring
- weighting
- compute a score between a query and each document
- develops several variants of term-weighting for the vector space model.
parametric and zone indexes
parametric indexes There is one parametric index for each field.
Zones are similar to fields, except the
contents of a zone can be arbitrary free text. Whereas a field may
take on a relatively small set of values, a zone can be thought of as
an arbitrary, unbounded amount of text. In fact, we can reduce the
size of the dictionary by encoding the zone in which a term occurs in
the postings.
Weighted zone scoring
How do we implement the computation of weighted zone scores? A simple approach would be to compute the score for each document in turn, adding in all the contributions from the various zones.
The reader may have noticed the close similarity. The reason for this will be clear as we
consider more complex Boolean functions than the AND; thus we may
assign a non-zero score to a document even if it does not contain all
query terms.
Learning weights
These weights could be specified by an expert (or, in principle, the user); but increasingly, these weights are ``learned'' using training examples that have been judged editorially.
For weighted zone scoring, the process may be viewed as learning a linear function of the Boolean match scores contributed by the various zones.
The optimal weight g
6.2 Term frequency and weighting
A plausible scoring mechanism then is to compute a score that is the sum, over the query terms, of the match scores between each query term and the document. Towards this end, we assign to each term in a document a weight for that term, that depends on the number of occurrences of the term in the document. We would like to compute a score between a query term t and a document d, based on the weight of t in d.
6.2.1 Inverse document frequency
Raw term frequency as above suffers from a critical problem: all terms are considered equally important when it comes to assessing relevancy on a query. In fact certain terms have little or no discriminating power in determining relevance.
The reason to prefer df to cf is illustrated in Figure 6.7 , where a simple example shows that collection frequency (cf) and document frequency (df) can behave rather differently.
Instead, it is more commonplace to use for this purpose the document frequency dft, defined to be the number of documents in the collection that contain a term t. This is because in trying to discriminate between documents for the purpose of scoring it is better to use a document-level statistic (such as the number of documents containing a term) than to use a collection-wide statistic for the term.
6.2.2 Tf-idf weighting
We now combine the definitions of term frequency and inverse document frequency, to produce a composite weight for each term in each document.
6.3 The vector space model for scoring
The representation of a set of documents as vectors in a common vector space is known as the vector space model and is fundamental to a host of information retrieval operations ranging from scoring documents on a query, document classification and document clustering.
6.3.1 Dot products
We denote by V~(d) the vector derived from document d, with one component in the vector for each dictionary term. Unless otherwise specified, the reader may assume that the components are computed using the tf-idf weighting scheme, although the particular weighting scheme is immaterial
to the discussion that follows.
6.3.2 Queries as vectors
To summarize, by viewing a query as a ``bag of words'', we are able to treat it as a very short document. As a consequence, we can use the cosine similarity between the query vector and a document vector as a measure of the score of the document for that query. The resulting scores can then be used to select the top-scoring documents for a query.
A document may have a high cosine score for a query even if it does not contain all query terms. Note that the preceding discussion does not hinge on any specific weighting of terms in the document vector, although for the present we may think of them as either tf or tf-idf weights.
6.3.3 Computing vector scores
In a typical setting we have a collection of documents each represented by a vector, a free text query represented by a vector, and a positive integer K. We seek the K documents of the collection with the highest vector space scores on the given query. We now initiate the study of determining the K documents with the highest vector space scores for a query.
6.4 Variant tf-idf functions
For assigning a weight for each term in each document, a number of alternatives to tf and tf-idf have been considered.
6.4.1 Sublinear tf scaling
It seems unlikely that twenty occurrences of a term in a document truly carry twenty times the significance of a single occurrence. Accordingly, there has been considerable research into variants of term frequency that go beyond counting the number of occurrences of a term.
6.4.2 Maximum tf normalization
One well-studied technique is to normalize the tf weights of all terms occurring
in a document by the maximum tf in that document.
6.4.3 Document and query weighting schemes
Equation is fundamental to information retrieval systems that use any form of vector space scoring. Variations from one vector space scoring method to another hinge on the specific choices of weights in the vectors V(d) and V(q) .
6.4.3 Document and query weighting schemes
In Section 6.3.1 we normalized each document vector by the Euclidean length of the vector, so that all document vectors turned into unit vectors. In doing so, we eliminated all information on the length of the original document; this masks some subtleties about longer documents.
(1) verbose documents that essentially repeat the same content – in these, the length of the document does not alter the relative weights of different terms; (2) documents covering multiple different topics, in which the search terms probably match small segments of the document but not all of
it – in this case, the relative weights of terms are quite different from a single short document that matches the query terms.
Of course, pivoted document length normalization is not appropriate for all applications. For instance, in a collection of answers to frequently asked questions (say, at a customer service website), relevance may have little to do with document length.
Comments
Post a Comment